There are so many pros on building an API that exposes our application resources. It’s particularly important to achieve reducing tiers coupling to the minimum, but even better, this allows different applications to access our resources. For well designed APIs this will also happen in an intuitive way.
But even the best APIs could be implemented in a way that the client needs to make a call every time it needs to know the state of a resource. For this case, the API will have to return the entire resource every time it’s requested.
But, wouldn’t it be more efficient if the API only returned what has changed since the last time it was queried? And wouldn’t it be even more efficient if the client didn’t need to call the API to check if something changed?
Streaming APIs (when implemented properly) try to solve exactly that. On this post we will see how these could be implemented and how streamdata.io works in order to turn a traditional API into a Streaming API.
Streaming APIs
A Streaming API is capable of sending notifications to the client.
In traditional HTTP (base protocol for webAPIs) schemas, the client sends a request to the server. The server receives it, understands, even call the proper listeners (if any) and ends returning a response to the client. On this schema, once the server sent the response, it can’t send anything else to the client until this one makes a new request.
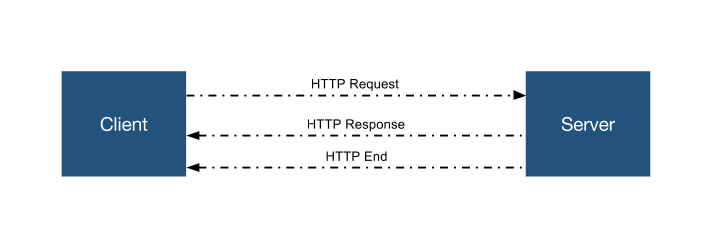
But it’s possible for our server to receive the request, process it and even send a response, but leave it on-hold instead of closing it. This way the server could keep sending information to the client for a long period of time. This technique is better known as long polling.

By long polling, our API could receive a call and provide the resource that is being requested as a first response. But instead of closing the connection, the API could send new responses in case the resource changes after the first response.
Furthermore, the API could send just the changes that impacted the resource.
Let’s consider the following example

1- Client 1 sends a request with method GET in order to request a book with id 123321.
2- The server returns a response to the client 1 with a 200 OK code and a JSON containing the book information
{
"id": 123321,
"title": "My book",
"ISBN": 123321,
"Edition": "4th"
"Year": 2015,
... // Let's assume a complex structure with a lot of fields
}3- Client 2 sends a request with method PATCH in order to modify the book edition (now “5th”).
4- The server sends a response to the client 2 with a 200 OK code.
5- The server sends a response to the client 1 with a 200 OK code and a JSON with the book information.
{
"id": 123321,
"title": "My book",
"ISBN": 123321,
"Edition": "5th"
"Year": 2015,
... // Let's assume a complex structure with a lot of fields
}Note: We are not going into any discussion about which methods should be used (PATCH o PUT) or which HTTP codes. This topics deserve their own post.
Because the server implements long polling, the API is able to notify the client that the previously requested resource has changed, without having the client sending a second request.
The process where APIs proactively notify the client about changes on the resources is known as Push Notification. It worth clarifying that long polling is not the only way of achieving this behaviour. WebSockets is another specification that does the trick.
Although the example shows the benefits of implementing Push Notifications as a feature of our Streaming API, the impact regarding to the performance is not neatly visible. Even though is true that the client won’t be periodically sending requests in order to check if the resource changed, each time the API makes a push it will be sending the complete resource to the client. By implementing a differential logic (server side), our API would be able to just notify the updates when sending a push. Considering our previous example, this could go like this:
{
"op": "PATCH",
"/Edition": "5th"
}This JSON informs the client that the field “Edition” has changed. It also informs its new value. The client is now able to update its model according to this information. This way regardless how big a resource is, the push is only sending the fields that have changed since the last update.
Request timeout
Avoiding infinite time requests is a good practice. Connections could timeout or even could be loss because of servers or network physical conditions. The code impact could be described (in a general way) as
- Server: Checks that the response is open before sending data.
- Client: Check that the request is active. Otherwise, make a new request.
In case of having too short timeouts, each new request would be receiving the complete resource (again). A known solution consists in sending the server the timestamp of the last received notification. This way, for every request that is not the first one, the server could respond with the updates happened since that timestamp. For a proper implementation, the server side logic should hold a change log of every resource.
This far we have covered an explanation about Streaming APIs and some impelmentation approaches. It’s not this post goal to show a whole concrete example.
From an API to a Streaming API
But, what happens when an API is not a Streaming API? The short answer is: We use it as a regular API. It means that, each time we need to know the state of a resource, we will be sending a request.
A more complete answer includes a proxy implementation capable of intercepting a request, storing the response, informing it to the original client, and repeat the operation as many time as needed. This proxy implements long polling which means that it is able to notify the client as soon as a change on a resource is detected. Next diagram shows this scenario.
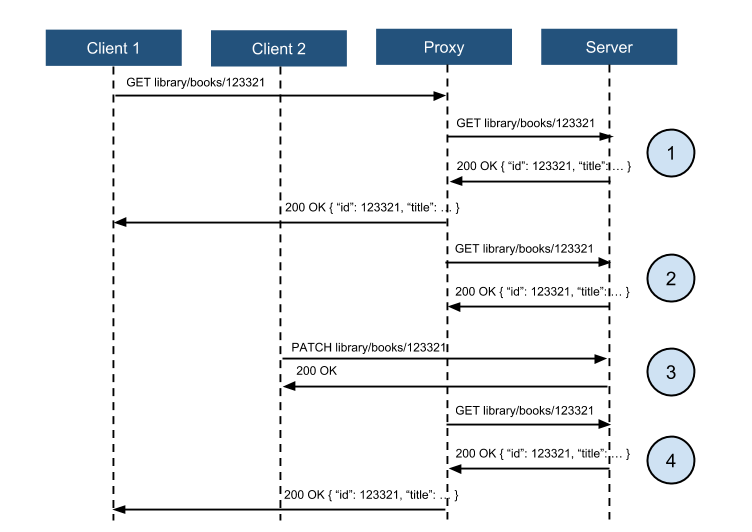
Let’s see what happens on each of the instants (1-4):
- Client 1 requests the “book” with id “123321”.
1.1 The request is not got by the server but by a proxy.
1.2 The proxy redirects the request to the server.
1.3 The server returns a response to the proxy.
1.4 The proxy redirects the response to the client. - The proxy sends a new request to the server (and it will do that every X seconds).
2.1 The server returns a response to the proxy.
2.2 The proxy compares the fetched resource during this request with the previous one and detects no changes.
2.3 The proxy doesn’t Push anything to the client. - Client 2 sends a request with a PATCH method.
3.1 The client sends the request directly to the server (there is no reason for involving this kind of proxy for a “write” operation).
3.2 The server sends the response confirming the operation. - The proxy sends a new request to the server (one of those being sent every X segundos).
4.1 The server sends a response to the proxy.
4.2 The proxy compares the fetched resource during this request with the previous one and detects changes.
4.3 The proxy sends a Push to the client informing the changes (ideally, just the news instead of the complete resource).
This way, and without modifying a single line of the API code, we can emulate the behaviour of a streaming API (from the client perspective at least).
What is most interesting about this implementation is that it’s not hard to make it generic for virtually every existing API. It means that we could implement a platform that offers this logic to an API users turning it into a streaming API transparently for both, the API provider and the client.
This is exactly what streamdata.io does.
Example using streamdata.io
Considering the service provided by BitcoinAverage, and looking at a simple method of its API, we will write a simple code that allows us to query the following resource every 5 seconds: https://api.bitcoinaverage.com/ticker/global/EUR/
<html>
<head>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js"></script>
<script>
setInterval(function() {
$.ajax({
dataType: "json",
url: "https://api.bitcoinaverage.com/ticker/global/EUR/",
success: function(data) {
console.log(data);
}
});
}, 5000)
</script>
</head>
</html>By using JQuery for getting the benefits of the ajax method and the setInterval function (that lets us execute a function repeatedly on a time interval basis) we get the following response on the console:

As it can be seen, the requests are being sent every 5 seconds and the complete object is being returned regardless if it was modified.
From the Network perspective we can also discover an interesting thing
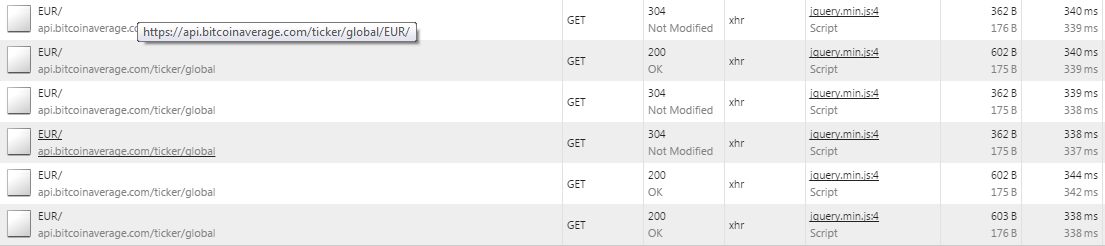
Each request is proven by a new GET. Also, some HTTP response codes are 200 OK while others are 304 Not Modified. This last code points that the resource hasn’t changed since last time it has been requested.
Using streamdata.io
Steps for getting started with streamdata.io are really simple and can be found on its web site. As a summary:
- Create an account.
- Once logged in we will see the Home page with a dashboard in it.
- Create an application (let’s call it “OutBitApp” for this example).
- Access the application.
- Check the configuration and make sure that the “Client Request Signature” option is disabled (only for this example, we want to avoid any not mandatory complexity).
- On that same screen we can see (and renew) the App Token (it will be required for authenticating the client code).
- Follow the instructions at the official GH repo in order to generate the SDK that lets us interact with streamdata.io.
Having accomplished these steps, the following code accesses the same API from the previous example but receiving Push notifications instead.
<html>
<head>
<script src="./js/streamdataio.min.js"></script>
<script>
var myEventSource =
streamdataio.createEventSource("https://api.bitcoinaverage.com/ticker/global/EUR/",*/APP TOKEN/*);
myEventSource.onData(function(data){
console.log("init")
console.log(data);
}).onPatch(function(data){
console.log("update")
console.log(data);
}).onError(function(data){
console.log("error")
console.log(data);
}).onOpen(function(data){
console.log("open")
console.log(data);
});
myEventSource.open();
</script>
</head>
<body>See the console</body>
</html>Note: The “APP TOKEN” must be replaced with the one generated for the application. Remember that JavaScript runs on any client/browser and because of that, it’s not a good idea to place the Token on that code. This is only valid for proof of concept and examples.
Let’s check the response at the console:
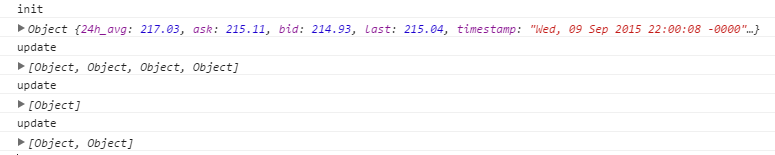
- Even though these are hidden, objects are not being logged in regular intervals. This is due to the client only logs those when it receives a response and this only happens when the observed resource changes.
- The first received object (logged after an “init”) is similar to the one on the previous example, it means, the complete object. The following ones (logged after an “update”) are actually arrays of objects..
Let’s analyze one of these arrays:
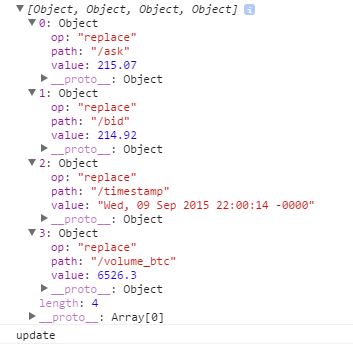
Each object in the array indicates that an attribute has been replaced, and its new value is specified. Not every array has the same length (4, 1 and 2 as can be seen on the previous image). This indicates the quantity of changes that has been detected on each response.
Finally, let’s see what happens on the network view:
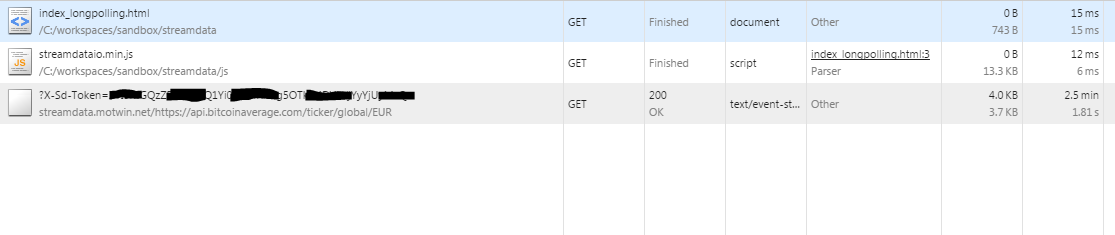
It can be seen an ONLY request to a url belonging to streamdata (the proxy) and as parameters, the token (only those clients knowing it will be able to access the app at streamdata.io) and the url of the original request. That request has been opened for 2.5 minutes receiving notifications every time the resource changed at the server.
Summary
It’s clear how practical and even how performant using a Streaming API could be. Only thinking of the current web applications helps us understanding how useful is to receive notifications when the model changes at the server.
But we won’t always count with a Streaming API. We are often hitting a 3rd party API and lot of times, our API already exists and we don’t count with time or money enough to change it (turn it into a streaming API). By implementing a proxy we can emulate that behaviour, and even if we didn’t count with the resources for implementing this solution, it would be possible to take advantage of a platform like streamdata.io that provides this functionality as a service in the cloud.