Hace unos (cuantos) años, hablar de escalabilidad traía a la mesa una serie de sorpresas de todo tipo. Gente hablando de escalabilidad como una cualidad del hardware, gente demasiado soprendida al escuchar que el que escala no es el hardware sino que las aplicaciones deben estar diseñadas de forma que puedan escalar, y por supuesto, la poca distinción entre escalabilidad horizontal y vertical.
Afortunadamente, en estos días, el concepto ha sido digerido, explicado y aparentemente entendido, pero sigue resultando curioso entender por qué durante tantos años, hubo tanta confusión al respecto.
No se si es causa o efecto de esta nueva era, pero la virtualización juega un rol principal, y especialmente, la virtualización mediante containers.
Este es el primer post de una saga de tres, en la cual se cubrirán los conceptos básicos de escalabilidad, el rol/cultura DevOps, introducción a Docker, una explicación y guía para su instalación, primeros pasos y configuración de una docker regisrty. En este primer post, DevOps, y escalabilidad.
Los DevOps
Durante mucho tiempo el rol del desarrollador se encontraba bien definido y diferenciado del rol del operador. El desarrollador construía software mientras que el operador se encargaba de la infraestructura y el deployment de los paquetes de software a instalar. La industria del software mantuvo con orgullo esta separación alegando que el desarrollador podía abstraerse por completo del hardware y el modo de deploy, concentrándose en escribir y refinar código. Empieza a ser menos sorprendente que muchos desarrolladores no pudieran escribir código escalable.
Al abstraerse por completo, el desarrollador no solo se despreocupaba del hardware y la plataforma que fuera a ejecutar sus programas; también se despreocupaba de la topología de dicha infraestructura. No era necesario saber si el servidor estaría corriendo en un Intel, AMD u otro fabricante, ni conocer el sistema operativo (en el caso de Java, se suponía que la JVM exponía una plataforma unificada). Pero tampoco parecía ser necesario saber si habría una máquina como servidor o si serían 10, si estarían en cluster, que pasaría si una máquina se encontrara apagada, etc. Como consecuencia, y a modo de ejemplo, guardar los datos del usuario logueado en una sesión HTTP resultaba tan sencillo y beneficioso que se convirtió en un dogma del desarrollo de aplicaciones web.
Si bien muchas de las abstracciones resultaron medianamente beneficiosas (medianamente: no resulta tan distractivo conocer el hardware donde correrá nuestra aplicación), otras se volvieron extremadamente inconvenientes. El desarrollo de aplicaciones que escalen es un claro ejemplo de los inconvenientes de la abstracción total.
El concepto de DevOps surge como una alternativa a esta abstracción (o al menos una redefinición). Si bien para la mayoría de las empresas DevOps es un rol más bien vinculado con el Ops, el concepto radica en una cultura de colaboración entre los desarrolladores y los operadores que beneficia el desarrollo, prueba, y releases frecuentes y confiables. Como un efecto colateral (positivo), los desarrolladores se involucran en forma temprana en el entendimiento de la infraestructura pudiendo tenerla en cuenta al escribir las aplicaciones (y descartando aquella información que no les resulte relevante).
Escalabilidad
Una aplicación escala si puede ajustarse a una mayor exigencia de carga.
Escalabilidad Vertical
Procesadores más potentes, con mayor cantidad de cores pueden procesar mayor cantidad de threads. Más memoria puede almacenar mayor cantidad de datos de los procesos en ejecución, y de esa forma, una aplicación puede soportar mayor carga. A este tipo de escalabilidad se la conoce como escalabilidad vertical.
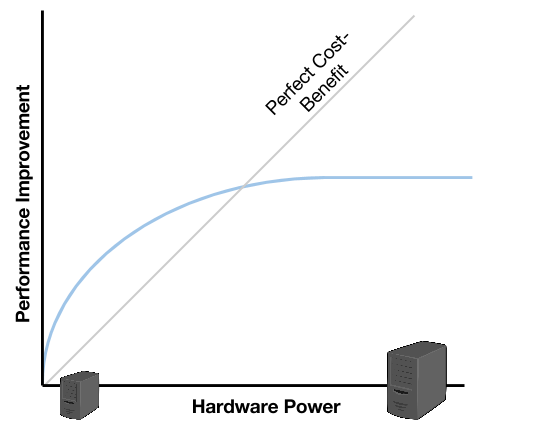
Una ventaja (relativa), es que puede lograrse aprovechando capacidades de los lenguajes más populares (como ser JAVA). Pero una gran desventaja es que, llegado a un punto, el aumento de performance en relación al aumento de carga se vuelve asintótico.
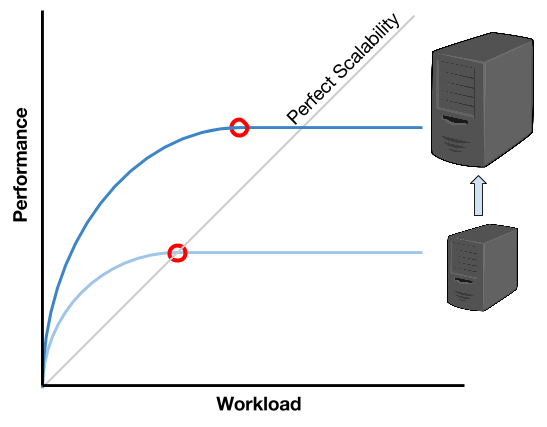
En la imagen se puede ver como, a medida que aumenta la carga, la performance aumenta cada vez con mayor dificultad hasta llegar a un punto en donde no puede aumentar más. Esto implica que todos los usuarios de una aplicación, comenzarán a experimentar una baja de performance, o incluso, una interrupción total del sistema.
Al escalar verticalmente, incorporando un servidor con mayores prestaciones de hardware, logramos mejorar la performance. Pero como se puede ver al comparar las curvas con la línea de escalabilidad perfecta (o escalabilidad lineal), el punto en donde el nuevo servidor deja de soportar la carga de trabajo, ocurre bastante antes de alcanzar la escalabilidad perfecta. Una progresión de este comportamiento indicaría que, en cierto punto, invertir en hardware más potente (y costoso), no lograría acercarnos a la escalabilidad perfecta, alcanzando un límite de escalabilidad (también asintótico).
Escalabilidad Horizontal
Para superar las limitaciones presentadas por la escalabilidad vertical, se produjo un cambio de paradigma en donde, en lugar de pensar en equipos con más potencia, se piensa en mayor cantidad de equipos con menor potencia.
A diferencia de la escalabilidad vertical, en este paradigma, la administración se vuelve más compleja, y el desarrollo necesita considerar el hecho de que el software estará distribuido en distintos equipos (con recursos separados). Pero, además de superar las limitaciones de la escalabiliad vertical, el hecho de poder escalar aumentando la cantidad de equipos (o nodos), termina siendo menos costoso e incluso, aprovechando técnicas avanzadas de virtualización como las ofrecidas por Docker, pueden automatizarse para responder dinámicamente a la carga en tiempo real.
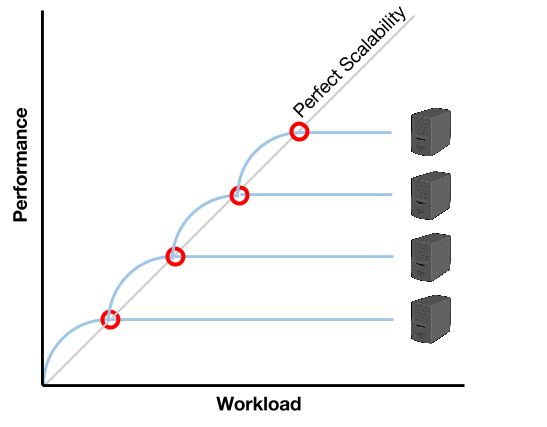
Como se ve en la imagen, hay un punto en donde un servidor ya no logra mantener la performance necesaria para soportar la carga. En el momento donde la curva de performance cruza la recta de escalabilidad perfecta (o quizás un poco antes), es tiempo de iniciar un nuevo servidor. De esta manera, por aproximación, se logra mantener una relación carga/performance que se ajusta a la escalabilidad perfecta y, en tanto y en cuanto el inicio de un nuevo servidor pueda realizarse de manera automática y veloz, el aprovisionamiento podría realizarse a demanda.
El concepto de virtualización mediante containers apunta exáctamente a brindar una solución para ese requerimiento. Como se verá en el siguiente post, Docker ofrece una manera más eficaz de virtualización que las tradicionales Virtual Machine, y si bien sus beneficios resultan instantáneos, se vuelven un verdadero diferencial al pensar en pequeños nodos que se levantan en cuestión de segundos cuando es necesario.
Como veremos también, el hecho de que estos nodos levanten tan rápidamente, es una combinación de las capacidades de la tecnología (que reutiliza el Kernel de un solo Sistema Operativo que ya está corriendo) y el diseño de componentes pequeños que levantarán al mismo tiempo en distintos nodos (reduciendo el tiempo de arranque y paralelizandolo).