Several years ago, speaking of scalability used to bring up a series of surprises of all kind. People talking about scalability as a hardware quality, people getting too much surprised when listening that it’s not the hardware just scaling, but the applications being written in such a way that can scale, and for sure, the little distinction between horizontal and vertical scaling.
Fortunately these days, the concept has been digested, explained, and apparently understood. However, I’m still curious about getting why this topic was source of so much confusion.
I’m not sure which ones is the cause and which one the effect of this new era, but virtualization plays a starring role, and specially the containers based virtualization.
This is the first of a three posts saga, in which I’ll be covering some scalability fundamentals, DevOps rol/culture, Docker introduction, installation walkthrough, first steps, and docker registry configuration. This first post is about DevOps and scalability.
DevOps
For so long, the developer role was well defined and set appart from the operator’s. The developer built software while the operator was in charge of infrastructure and software packages deployment. The software industry was proud of this separation claiming that the developer could (and should) be completely abstracted from hardware and deployment, in order to focus in writing and refactoring code. Finding developers having troubles trying to write scalable code is not that surprising anymore.
Not only was the developer totally isolated from hardware and the platform running the programs, but also was unworried about that infrastructure topology. It was not necessary to know if the server was going to be running on an Intel, AMD or other vendor, neither to worry about the OS (for instance, Java was supposed to be multi-platform thanks to the JVM exposing a unified one). But it also seemed to be unnecessary knowing if the server was going to be running in 1 or 10 machines, if it was going to be a cluster, what would happen if a machine was down, etc. As a direct consequence, and this is just one of many examples, storing the logged in user data on the HTTP session was so simple and useful that had been quickly adopted as a web applications development dogma.
Even though many of these abstractions turned to be reasonably profitable (reasonably: it isn’t that distractive to know the hardware where our application will run), others have become extremely inconvenient. Scalable applications development is a clear example of the troubles that come with the total abstraction.
DevOps concept stands up as an alternative to this abstraction (or a redefinition at least). Though most of the companies think about DevOps as a role mostly biased to the Ops part, the concept represents a culture where collaboration between developers and operators benefits frequent and reliable development, testing and releases. As a (positive) side effect, developers get into infrastructure early enough to consider it when writing applications (and dismissing that information that doesn’t add any value).
Scalability
An application scales if it’s able keep its performance over a workload increase
Vertical Scalability
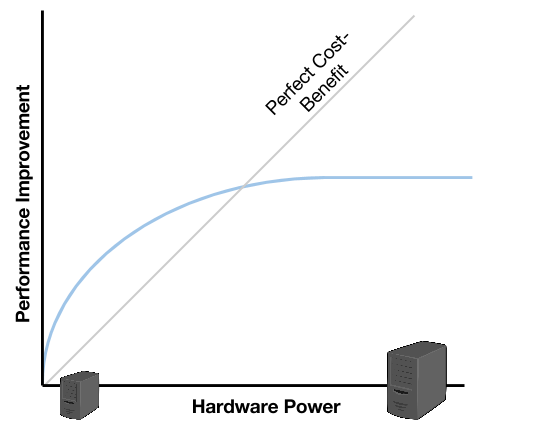
More powerful processors, with more cores, can process more threads. More memory can store more running processes’ data, and that way, an application can support a higher workload. This kind of scalability is known as vertical scalability. A (relative) advantage of this approach, is that it can be achieved by taking advantage of most popular languages capabilities (such as JAVA). But a big disadvantage is that, at some point, the relationship performance increase over workload increase becomes asymptotic.
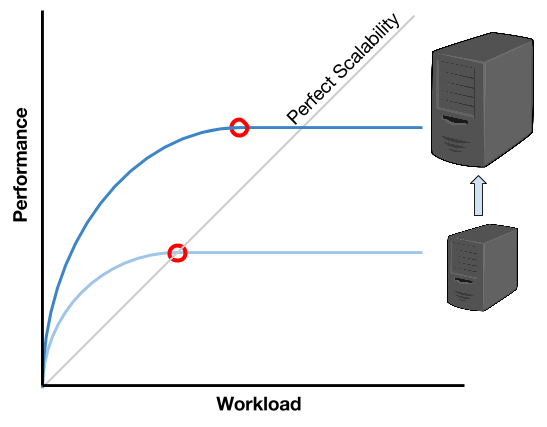
The previous image shows that as far as the workload increases, the performance increase becomes harder, until reaching the point of no increasing any longer. This means that every user will experience a performance degree, or even worst, a complete system interruption.
When verticaly scaling, by adding a more powerful server we are able to improve the performance. However, when comparing the curves against the perfect scalability the moment when the new server stops supporting the workload happens pretty earlier than achieving the perfect scalability. A progression over this behaviour would conclude that, at some point, investing in more powerful (and expensive) hardware won’t help us to achieve the perfect scalability, but it will reach a scalability limit (also asymptotic).
Horizontal Scalability
In order to overcome the limitations of vertical scalability, a paradigm rupture occured and, in place of thinking about more powerful machines, the key seems to be to think about more qunatity of less powerful machines.
Unlike with vertical scalability, in this paradigm, the infrastructure administration becomes more complex, and the development needs to consider the fact that the software will be distributed among different machines (with physically separated resources). But, in addition to overcomming vertical scalability limitations, the fact of being able to scale by augmenting the quantity of machines (or nodes) ends up being cheaper and furthermore, by taking advantage of the advanced virtualization techniques such as the ones offered by Docker, administration can be automated to dynamically adapt to the changing workload in realtime.
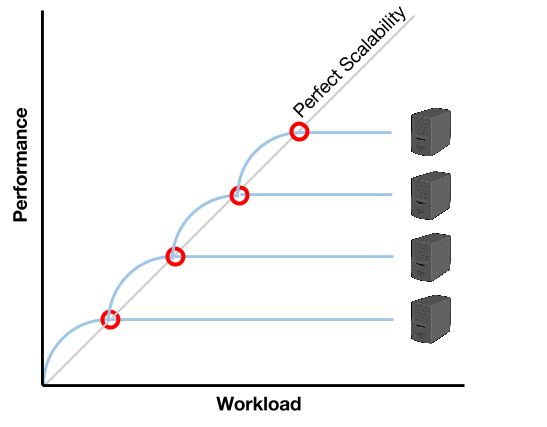
The previous image shows that there is a moment when the server is no longer able to support the workload. At that moment (when the performance curve touches the perfect scalability, or maybe a little bit earlier), it’s time to start a new server. This way, by aproximation, the workload/performance relationship can be maintained close to the perfect scalability. Furthermore, if the new server starts automatically and quickly enough, the provisioning could be done in an on-demand way.
Container based virtualization aims exactly to provide a solution for that requirement. As it will be covered on the following post, Docker offers a more efficient virtualization than the traditional Virtual Machines. And even though the benefits appear immediately, they become a real difference when thinking of small nodes that start in seconds when it’s necessary.
We will also see that, the reason for these nodes to start that quickly, is a combination of the technology capabilities (that reuses a unique OS Kernel that is already running) and the good design: small components that start at the same time in different nodes (reducing the starting time by starting in parallel).